Copyright Notice: This article is Copyright AI Factory Ltd. Ideas and code belonging to AI Factory may only be used with the direct written permission of AI Factory Ltd.
A key resource we have made use of are beta testers. They not only provide valuable input but have actually been central for developing our Spades engine. However this is more than processing a posted beta comment but a well-organised bit of engineering to allow deep analysis of reports. This article details what we have done.
Background
We have had informal beta testers since our start in 2003. These often manifested as a screenshot plus some comment. This was entirely adequate for our early apps, such as chess, where a simple screenshot conveyed the entire story. However in more recent times almost all our beta input has been for our game Spades, which has incomplete information. For a start we cannot analyse the position from a screenshot as it does not expose all player's cards and also fails to expose which cards have been played. There is almost nothing we can do with such a screenshot and even less with general comments such as "my partner overtrumped me". We need much more.
Posted game Records
The first step was to provide users with an extra in-app button that allowed them in a single action to create an e-mail that contained the deal seed and game record, where they could also provide a comment. We received something like this:
| The hand before this my partner thru a spade to win a hand when he went nil. And then followed up this hand throwing a club. He could have thrown the club on the previous hand to not win the hand. | |
| Version = 0KT | |
| Seed = 369875051 | |
| Joker settings = Normal | |
| Pro Mode = true | |
| Speed Play = false | |
| Aggressive Bids = 5 | |
| Encourage Nils = 3 | |
| Hands Played = 1 | |
| Score after hand N/S = 70 | |
| Score after hand E/W = 142 | |
| Bags after hand N/S = 0 | |
| Bags after hand E/W = 2 | |
| Play Levels (S,W,N,E): N/A, 28, 14, 28 | |
| Play Styles (S,W,N,E): N/A, 128, 0, 0 | |
| AI Type (S,W,N,E): N/A, 1, 1, 1 | |
| Lead Lowest Club: false | |
| Card Passing: iBlindNilPassingAllowed = TRUE, iNilPassingAllowed = TRUE, iAllow2cardPassing = FALSE | |
| Play To: 500 | |
| Ten Bag Penalty: 100 | |
| Blind Nil Gap: 100 | |
| Nil Bonus: 100 | |
| Break Spades: 0 | |
| Overtrick Pts: 1 | |
| 10for200 Penalty: 200 | |
| S Bid: 7 | |
| W Bid: 0 | |
| N Bid: 0 | |
| E Bid: 3 | |
| S Pass: NULL | |
| W Pass: 9S | |
| E Pass: 2H | |
| N Pass: JS | |
| S Pass: 4C | |
| E Pass: NULL | |
| S Play: AD | |
| W Play: TD | |
| N Play: 6D | |
| E Play: QD | |
| … | |
This was an essential first step and in early iterations we would type in the moves from the record and type in the parameters they chose, and we could then see all hands and examine the individual play they were critical of. This allowed us to see the exact situation in question.
However the beta tester may well be much more expert than us so we needed a means of further analysing the position. A problem is that given all cards it's too easy to analyse only in terms of what cards were dealt. This is misleading as you need to assess play in terms of what the other player cards might have been. We needed some console analysis tools.
The First Step: A multiple replay command
The game engine depends in some degree of chance as it predicts randomised versions of what the opponent's cards might be. If a beta tester reports play X then perhaps X was a very remote chance, or maybe th engine always played it (?). Our Spades engine chooses moves using a Monte Carlo search where each root branch was started with a different start deal, which was skewed by the play inference system (see Figuring out the Opponent's hand in Spades and Searching the Unknown with MCTS). So during analysis the game engine was being presented with different versions of what the other player cards might be, directed by the play inferences (e.g. a nil bidder is unlikely to have a fist full of high spades).
The solution was a simple console command that repeatedly re-played the move, each time resetting the random seed before analysis. The program was basically re-playing the same play over and over again and the console simply counting how often each play was made.
In the sample below (from a real beta report, with our verbatim response) the issue was that North appeared to fail to support South's Nil bid. This was superficially a bad play. Note this hand is unusual as two players bid Nil, which makes assessment more complex. With double Nil, players find they have 4 competing objectives: 1. Defend our Nil, 2. Attack opponent Nil, 3. Defend our non-nil bid and 4. Attack the opponent non-nil bid.
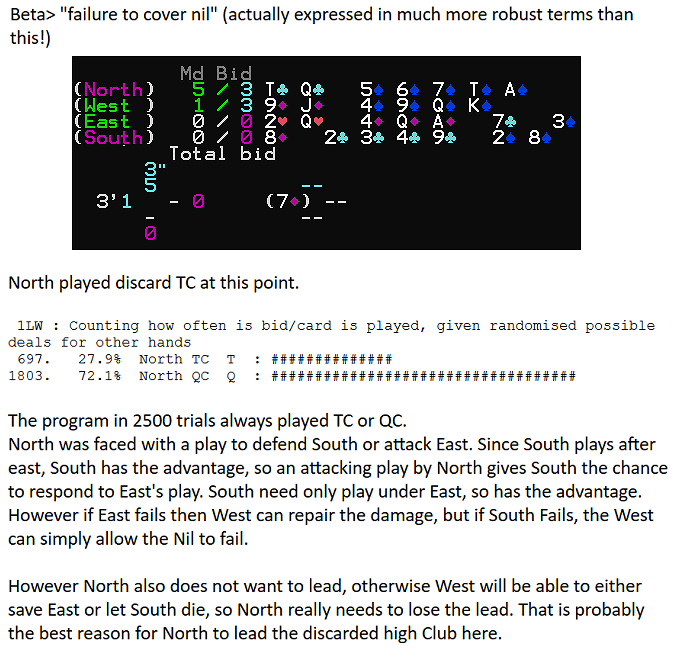
Here we ran 2500 replays of the move and the program chose to play QC 72.1% of the time and TC 27.9%. It never chooses to play a spade. A quick examination of the cards shows that JC has already been played, so QC and TC are equivalent cards. Therefore you might expect that they would be chosen 50% of the time each. Checking the immediate pre-search analysis shows though that it understands that these cards are equivalent, so that one of them (TC) has an evaluation skew placed on it early in the search to discourage its selection. This is not enough for it not to be chosen occasionally but avoids the program excessively wasting time searching equivalent moves. This skew mechanism is an important part of evaluation and such beta cases can expose where the skew is ill-directed.
Of course we also have immediate access to any play analysis and part of this is examining the North's expectation of what each player holds, as follows:
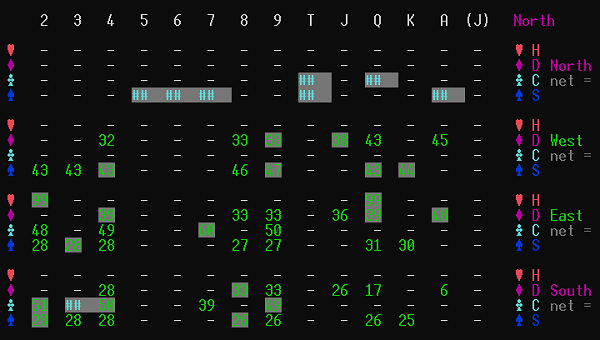
A critical consideration might be assessing the danger that South is more likely to hold a higher card than 7D than East, who also bid Nil. From above we see that play inferences suggest that East is more likely to hold higher diamonds with the following percentage chance of holding the remaining top diamonds:
33 33 36 39 48 total 189
Whereas for South we see:
33 33 26 17 6 total 115
Since South plays after East it also can choose to just play under East, so has an advantage there as well.
All this adds up to affirming that the risky failure to take the trick with a trump is more likely to hurt the opponent than partner.
In this case, with the advantage of seeing all cards and analysis above, we can answer the beta tester query. We also know that the program was never going to play a spade. However our response depends on our own analysis of the play. In this instance maybe we can be reasonably confident, but quite often play issues are much more subtle.
What we have not offered above is any measure of the relative advantages or consequences of any particular play. Note also that our analysis may simply be wrong as our core basis is based on just what the program is likely to play. If the program has made a mistake then the multi-run will not expose this.
We need more.
The Second Step: Multiple full evaluation playouts: "Deep rollouts"
As indicated above the multi-layout is just a repetition of the original analysis. What we need is something more profoundly deeper. Turning up the search depth alone is actually not enough. The number of extra nodes needed to make a quantum change in performance is prohibitive. The depth of the search to final card could be 52 plies. You have to search for an extraordinary length of time to build a near complete tree.
An alternative is to analyse each possible play and for each of these choices, analyse and play out all plays until the end of hand. This means in the above situation, where there are 27 cards left to play, we have to do a full search on each of the 27 serial plays in turn, accepting the choice at each point and starting again with a full analysis of the next play. At the end of the playout the net scores are added to the root play. This is repeated for each possible play and the whole procedure repeated (say) 400 times. At the end of the analysis you can then assess the average score that each play delivers.
Of course in each of these 400 playouts we actually need to modify the deal based on play inferences. This idea is already used within any one search but the move selection inside it is relatively simple and the re-deal vanishes as soon as end-of-hand is reached. In this case the re-deal needs to continue after each play. These requires an initial re-deal to be re-used in the entire playout.
At the end of this analysis we can see below the result (only performing 200 rollouts, not 400).

From this we can see that the deep analysis affirms the choice of TC or QC. Note that at times this second deep analysis might overturn our initial assessment. Here we see though that NS expect to lose overall, by over 30 points. Playing a spade instead though offers an expected loss of 75.44 points for 7S and 123.46 points for AS. This analysis can take up to 2 hours to complete on a fast Ryzen PC.
With this analysis we can be more confident that our assessment is correct. Of course it is not guaranteed as the deep rollout is still fundamentally built around the core engine that may have made a bad play. However it is substantially stronger than any single search.
The Third Step: Increasing the efficiency of report processing
Very quickly it became obvious that we needed better automation so the updated reports had 32 #defines added that could be directly compiled in to test the specific ruleset, also which AI opponents were in play and the running score and bags totals. The other step was to support easy pasting of the moves list into the console. Without this it took too much work and errors were made. This allowed more beta reports to be processed quickly.
The Final Step: Allowing manual testing of possible deals
Even with all of the above in play the reason for a move may still be hard to understand, even if the console was telling you it was correct. Of course you anyway can easily manually play the existing hands, but it does not cover the range of likely possible deals. A solution to this was to add a command that created a random re-deal at the contested play point and then just play it out manually. There have been a few instances where this was the only way we could comprehend why the best play actually was the best.
Conclusion
These tools, combined with the previous many generic tools (see Get Tools right… (The Rest Will Follow!)) have deeply impacted the analysis we can do on our AI. In this instance the beta reports have been by far our most profound and useful input into development. The beta testers spot things that we would not see in play testing and can encapsulate any potential issue into one precise test example.
From this you might imagine that our program is being endlessly modified in response to new reports. However, in practice, only a tiny proportion of these actually reveal a real issue. The most common situation is simply that the beta tester, who is unable to easily count cards, fails to appreciate that an apparently dumb move is a good one. Of course it reveals aspects of human play. If a player or player's partner bids nil then a human player will try and defend it to the last card. However the AI can spot when the cause is essentially lost and instead switch to attacking the opponent's or defending the partner's bid. This may look irrational but may make perfect sense in terms of maximising points.
We now have a Spades game engine that is very complex, but appears to generally play very well. It is perhaps the last serious attempt by AI Factory to create a game engine using prescriptive AI, which increasingly is being overhauled by newer deep learning methods.
Jeff Rollason - September 2020
