Copyright Notice: This article is Copyright AI Factory Ltd. Ideas and code belonging to AI Factory may only be used with the direct written permission of AI Factory Ltd.
This is a follow-on to our previous article The Rating Sidekick that showed how the methods used for developing the program Shotest to play world class Shogi (Japanese Chess) were adapted for use with the generic framework used for our engines. This article shows how this has now been substantially advanced to make it more powerful still.
The Background
The core problem being addressed here is how to manage the prototyping and testing of game-playing AI programs to make them stronger. The reader is recommended to examine the article referenced above (and its referenced articles), which discuss the issues in depth. So many obvious paths are actually fraught with many pitfalls.
The article above reaches a point where the development is provided with a solid basis for controlling testing, removing some of the administrative complexities and exposing what needs to be tested next. The glue that held this together was the RATING program that provided a sensitive method of cross-comparing sets of results. This was ELO-like in its output, but much more sensitive and useful than ELO.

What Was Missing?
The system above completely replaced the approach for version testing and provided some degree of automation in that the RATING program managed the strength assessment from multiple version tests. The naming convention that this was built around also exposed which versions used which options, pointing at follow-on tests that might be tried. The RATING program also exposed versions had not been so thoroughly tested so that follow-on tests could be planned. Since the configuration of each version was embedded in the version name, it was easy to see what switches each version used.
However, this system, although powerful and carrying much of the developer's administrative and results analysis burden, invited some traps as it did not easily expose whether any one version has met the same opponents as another tested version. To some degree this could be solved by sorting the rating test file, so that each version was grouped. This works for a small volume of cross-testing, but becomes harder work once the tests mount up. Failure to get well matched test sets could result in inaccurate ratings.
Another feature missing, which was present in the original Shotest development system, was a separate assessment of each feature being tested. To create this value required the detection of two program versions that differed in only one test switch. This difference might occur in several different pairs of versions and from this it could be seen whether the switch made the versions stronger or weaker.
The Testbed Expansion
The first step was to take this system, designed first for the game Spades, to become a truly fully generic component in our testbed. This would make it automatically available for any game under development. So, the generic console now supported commands for this processing, including setting up of version switches by simply pasting in the name of the version test switches under test. i.e. "S3_____B7_E2_K2_W1" defines a set of tuning and feature switches, which are displayed on test output, but now the console could set all these switches in a single step.
The RATING program could now also be run from the console and then further analysis completed from there.
The original RATING runs though were completed from a command console and generated a single output of the type below (truncated to fit, but showing current Spades test results).
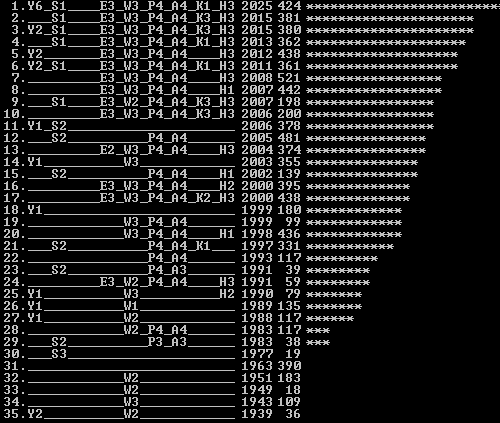
This output exposes which switches appear to offer benefit. In this case options Y2+Y4 = Y6 are successful (Note there are separate combined binary switches here, Y1, Y2 and Y4.).
The new expanded system provides a console command that takes this table, and the rating file, and further analyses it to provide a more substantive breakdown, as follows:
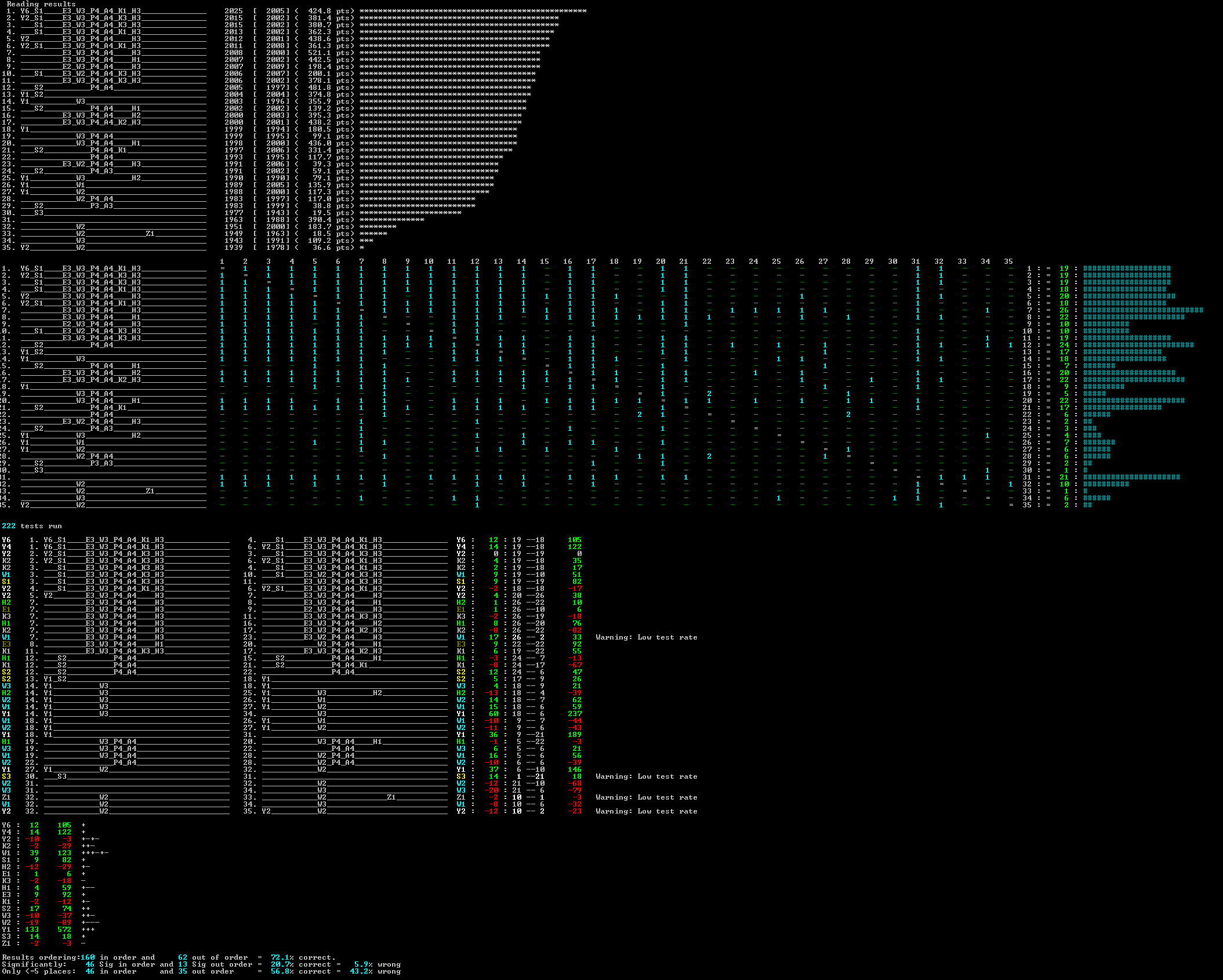
This table above cannot be fitted inside this article 500 pixel width limits imposed by the newsletter, so you will need to click on the image to see it in a separate window.
The Cross-Reference Table
The first helpful new analysis here is simply a cross-reference table showing which version has played which version. This is critical as some lower test versions may generate untypical results, so if two versions have not both played this same other version, then this might critically distort the rating result. As can be seen here the top three rated versions have each played the same opponents.
Note also that the graph at the end of this table shows how many opponents each version has had. This is a quick easy check. If the rating of several top versions depends on an opponent that is not well tested, then this provides an obvious cue to provide further tests. In this case version 9 has only had 10 opponents, but most of the top versions have played it. If any of the top ordering particularly depended on good performance against this version, and it is overrated, then extra tests may expose version 9 as weaker and so the ordering may change.
In this case though testing ended as the top-rated version is clearly significantly ahead of other versions.
The Switch Assessment Table
The next table analysis picks out instances where two versions differ by just one switch. This also includes some switch pairings where the switch is part of the same switch type. e.g. the first switch is Y6, which is switch Y2 + Y4 combined. This top table line shows which versions delivered this test comparison and the net difference in rating. In this case for Y6 the rating improvement was 12. Following that the table shows "19-18" which indicates the number of opponents each of the versions used for their test rating. In this case 19 and 18 are high values so the final scaled rating different is expanded to 105 at the end of the line to reflect that the rating difference is significant.
If you scan further down you see that on the 15th row that switch W1 (highlighted in cyan) delivers a greater rating improvement of 17 than the 12 above, but that line is flagged with "Warning: Low test rate". This value depends on comparing a version that has played 26 opponents with a version that has only played 2 opponents. In consequence, the scaled weighting of this is only 33. So, the net scaled rating of 33 for this is less than Y6 on the first line, net rated 105, even though the rating difference is higher.
If you scan the complete list you will see that W1 is tested in 6 lines, each providing a net weighting component.
The Switch Summary Table
Below the above is a much smaller table that summarises the switch assessments. This gives a net raw rating difference, which sums the difference in rating for each comparison; and net weighted difference, which sums the weighted difference in rating for each comparison. The latter value is more meaningful. Finally, a simple list of +/- is shown which logs how many comparisons improved and diminished the rating. In this case Y1 has "+++" and a high weighted value, so we can be very confident that switch Y1 is good.
The switch W1 has 6 results, with 4 better and 2 worse and a relatively low weighted value, so the confidence is less.
What does this give the Developer?
It is very easy to consume much more time setting up tests than time working on the AI. The tests themselves can take a long time to run, so it is imperative that you test the right thing. Without this analytical tool, it would be easy to make mistakes in drawing test conclusions and easy to overlook where a switch might work very well. Overall this enhanced testing process is easier and much faster.
A key issue also is that evaluation switches are rarely completely independent in their effect. You may find that one switch on its own will appear to make the program weaker, but when combined with another switch it then makes it stronger. The reason for this is that any one switch may be optimised to work best with many other ill-tuned switches. Once another switch is adjusted then the switch to be added may now no longer need to compensate for the bad tuning of another switch, so now works.
Limitations
This system is bound in with the 32-bit characterisation variable that is core to the AI framework. This characterisation variable is designed to add features such as aggression and timidity, which use 6 bits. This leaves just 26 bits for switches. In addition, there is a 32-bit AI type which can also be used. We have essentially hijacked the characterisation system for version testing, which is not ideal, but it works.
This capped set of switches is more limited than the Shotest development, which had no upper limit, but the Shotest system could only work with hard-wired binaries, so was less flexible. The new system has the convenience of allowing multiple different switch tests using a single binary.
Code Support for Switch Testing
Since the developer is confined to work with a smaller number of switches, this needs to be combined with a regime of conditional compilation. A switch can be temporarily retired and recovered for re-testing by controlling it with a numbered "RETIRE" define, as follows:
#define RETIRE17 1 // "feature X" 0=switch active,1= hardwired on, 2=Hardwired off
#if RETIRE17==0
If ( iFb_EngPlayer.Cp_Test_SpecialStyle(2) ) // switch test
#elif RETIRE17!=2
{
test code
}
#endif
With so many switches floating around and being enabled and disabled it would not be hard to accidentally find that a switch was re-used by accident or tested when disabled. To avoid this the switch test above "iFb_EngPlayer.Cp_Test_SpecialStyle(2)" actually is providing a bit mask to test, so that it returns TRUE if (switch&2) is non zero. This detects if a switch is being tested that is not active by building a map of switches being tested and comparing that with switches that are active. If a version appears to test a switch that is not active then a warning is issued and a correction can be made.
In addition, the range of switches currently in use can be displayed by running a game and then typing a command to display which switches are active and which unused. This is much more reliable than simply keeping a manual record of which switches are in use.
All this adds to the development reliability so that mistakes can be easily avoided. If just one switch is doubled up then the results could be rendered meaningless, so it is essential to avoid such errors.
Conclusion
It is hard to stress the advantage of this system enough. Without it we would have had a very inferior product.
This complete testing system offers a feature that was crucial in the success of Shotest: the capacity to hold switches in the test version until such time that they can later improve the program. So often a switch, that should make the program stronger, fails to do so until it is combined with some other switch. Therefore, switches can be retained and tested and re-tested until the time that they show a benefit.
This system is ongoing in its evolution but with each iteration it is very clear that the rate of progress accelerates. Where previously development had been stalled, this testing system exposed where progress can be made.
Of course, the complexity of this front-panel to testing has the capacity to pull the developer away from spending more time on the actual AI code, but experience has shown that this is an indispensable tool with a very clear net benefit.
Jeff Rollason - August 2017
